A Generative Engine Optimization Case Study
How GEO turned Knight Training Institute into acited authorityacross Google AI Overview, AI Mode & Gemini.
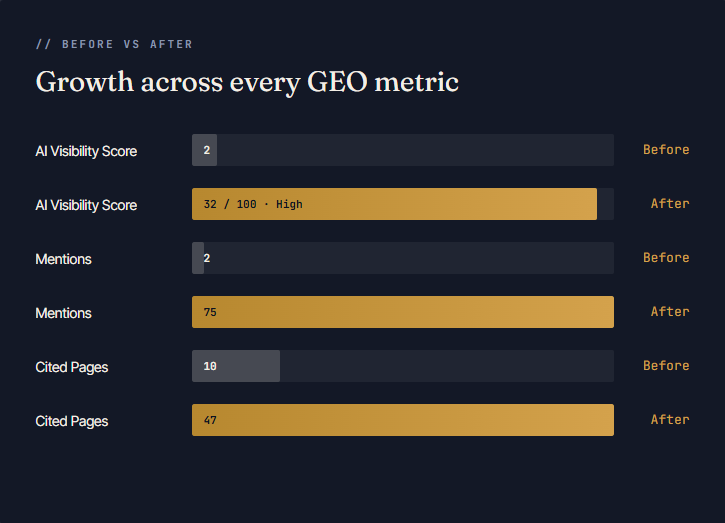
A six-month Generative Engine Optimization program — engineered to make a regional NYC training brand the source LLMs reach for first. From a baseline AI Visibility Score of 2 to 32, with 75 mentions and 47 cited pages.
Client- Knight Training
ktinyc.com
Discipline - GEO
Generative Engine Optimization
Engines Targeted- 4
Reporting- May 2026
Semrush AI Toolkit
A Primer
What isGEO?
Traditional SEO
Earns clicks from a list of blue links. Success is a position number on a SERP.
GEO
Earns mentions inside the AI-generated answer itself. Success is being the source the model quotes.
The Discipline
Generative Engine Optimization is the practice of engineering content, structure, and authority signals so that large language models — the engines now powering Google AI Overview, AI Mode, Gemini, ChatGPT, and Perplexity — reliably surface your brand as a source inside their generated answers.
The shift is fundamental. When an LLM answers a query, it doesn't return ten links. It returns one synthesised response, citing a handful of sources. Either you're inside that answer — or you don't exist for that query.
GEO is how we make sure you're inside it. It blends content architecture, semantic engineering, structured data, entity reinforcement, and third-party authority signals — all tuned to how LLMs actually retrieve and rank evidence.
Outcomes At A Glance
Six months ofFocused GEO.Four metrics that moved.
The GEO Problem
Knight had SEO authority.It had noGEO authority.
Ranking on Google is no longer the same as appearing in Google's answer. Knight's content was indexed, ranked, and visible to humans — but invisible to the models that now answer most questions before a click ever happens.
01 / The Symptom
A 2/100 AI Visibility Score
When the engagement began, Semrush's AI Toolkit reported only 2 brand mentions and 10 cited pages across every monitored generative engine. Zero ChatGPT exposure. Minimal Gemini and AI Mode presence. For competitive NYC security-training queries, the LLMs were citing nationwide operators instead.
- 2 total brand mentions across 4 LLM engines
- 10 pages cited — most accidental, not engineered
- Zero presence in ChatGPT answer streams
- Brand "invisible" to AI Overview for high-intent prompts
02 / The Diagnosis
Content built for humans, not LLMs
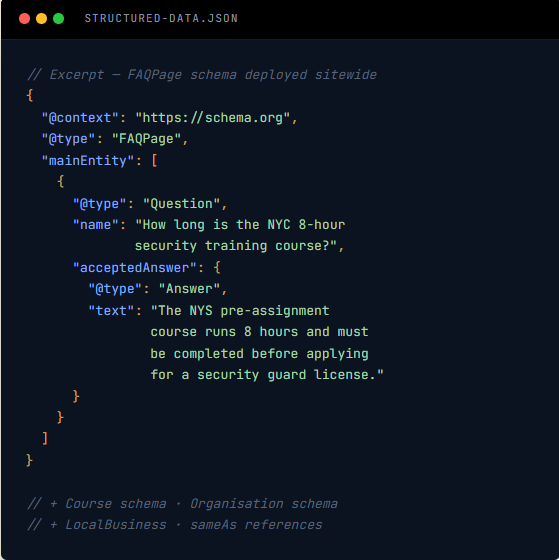
The site read well to a person, but it was structurally illegible to a language model. Answers were buried inside marketing prose. Entities were inconsistent. Schema was thin. Third-party evidence — the trust signal LLMs lean on hardest — was scattered. Every one of these is a GEO failure mode.
- No question-led content blocks LLMs could lift cleanly
- Sparse structured data — FAQ, Course, Organisation schema missing
- Inconsistent entity language across service & location pages
- Weak third-party corroboration on directories & review surfaces
The GEO Methodology
A six-stage framework, built forhow LLMs actually retrieve.
Every stage targets a specific way models decide what to cite — from how they parse a page, to how they verify a claim, to how they choose between two sources making the same statement. Run sequentially, the stages compound.
01
Stage 01
LLM Audit & Prompt Mapping
We catalogued every real-world prompt a Knight prospect sends an LLM — comparative ("Knight vs Allied"), informational ("how long is NYC security training"), navigational ("where do I take the 8-hour course") — and mapped each to a page that should win it.
What We Built
- Prompt taxonomy across 4 intent classes
- Engine-by-engine baseline visibility audit
- Competitor citation map — who wins what, and why
- Page-to-prompt assignment matrix
02
Stage 02
Answer-First Content Architecture
LLMs prefer self-contained, quotable answers — not marketing prose with the fact buried in paragraph four. We rewrote core training, eligibility, and certification pages so every answer leads, is structured, and can be lifted verbatim by a model.
What We Built
- Lead-with-the-answer page openings (TL;DR blocks)
- Definition-style sentences for every key entity
- Comparison tables LLMs can parse row-by-row
- Q&A blocks matched 1:1 to mapped prompts
03
Stage 03
Semantic & Schema Engineering
Models attach facts to entities. If your brand isn't a consistent, machine-recognisable entity, your claims attach to no one. We tightened entity language across the site and deployed the structured data LLMs actually use as a parsing shortcut.
What We Built
- Organisation, Course, FAQPage, & LocalBusiness schema
- Consistent entity naming across every page
- Internal linking that reinforces topical clusters
- sameAs references linking the brand to trusted profiles
04
Stage 04
Third-Party Evidence Building
LLMs corroborate before they cite. A claim that only appears on your own site is a weak signal; the same claim echoed across directories, reviews, and editorial sources becomes a fact the model will repeat. We built that echo deliberately.
What We Built
- Prompt taxonomy across 4 intent classes
- Review-platform alignment (consistent NAP & descriptors)
- Editorial placements citing Knight by name on topic queries
- Wikidata & knowledge-graph hygiene
05
Stage 05
Continuous LLM Monitoring
SEO tools track rankings. GEO needs to track citations — which engines are quoting which pages, for which prompts. We ran weekly visibility checks across all four engines and fed every change back into the content roadmap.
What We Built
- Weekly Semrush AI Toolkit visibility tracking
- Per-engine citation dashboard (AI Overview, AI Mode, Gemini, ChatGPT)
- Prompt-level win/loss reporting against named competitors
- Citation-quality scoring — own pages vs third-party
06
Stage 06
Iteration & Defense
GEO is not a one-shot project. Models retrain. Competitors react. Algorithms shift. We treated every monitoring cycle as input: reinforcing pages partially cited, rebuilding pages losing ground, and defending wins with fresh corroboration.
What We Built
- Bi-weekly content tuning sprints
- Reverse-engineering of competitor-cited pages
- Fresh evidence injection on plateauing topics
- Defensive content for high-value won prompts
Inside The Playbook
Ten tactics that did theactual work.
The methodology gives you the stages. These are the specific moves inside those stages — and the reason each one moves the needle on LLM citation.
01
Lead With The Answer
Every page opens with a clean, self-contained 1–2 sentence answer before context, history, or marketing copy.
Why - LLMs preferentially extract leading sentences when summarising a source.
02
Question-Style Subheadings
H2s and H3s phrased as the actual questions users ask — "How long is the NYC 8-hour security course?" — not topic labels.
Why - LLMs preferentially extract leading sentences when summarising a source.
03
FAQPage & Course Schema
Structured data deployed for every training program, eligibility rule, and certification path on the site.
Why - Schema gives LLMs a parsing shortcut they trust over inferring from prose.
04
Entity Consistency Sweep
One canonical name, one canonical description, one set of attributes — repeated identically across pages, schema, and external profiles.
Why - Inconsistent naming fragments a brand into multiple weak entities in a model's index.
05
Comparison Tables
Side-by-side tables for "Knight vs [competitor]" and "Course A vs Course B" — structured rows LLMs can read as facts.
Why - AI Overview lifts tables almost verbatim for comparative queries.
06
Cite-Worthy Statistics
Specific, attributed numbers — pass rates, course hours, certification timelines — placed where models can extract them.
Why - LLMs cite sources that supply concrete data over those offering generalities.
07
Directory & Review Alignment
Same name, address, descriptors, and category labels across every external listing the brand appears on.
Why - Cross-source corroboration is one of the strongest signals an LLM uses to decide what to trust.
08
Editorial Mention Building
Securing brand mentions in topical articles and industry pieces that LLMs already crawl for their corpus.
Why -Third-party mentions act as votes of confidence inside the model's training and retrieval data.
09
Internal Topical Linking
Pages within a topic cluster link tightly to each other, reinforcing topical authority for the brand entity.
Why - Tight clusters tell models "this site is the authority on X" rather than "this site mentions X".
10
Freshness Maintenance
Date-stamped revisions, current year references, updated stats — keeping every key page demonstrably current.
Why - Generative engines down-weight stale content for time-sensitive answers.
Under The Hood
A worked example: how a single page gotbuilt to be cited.work.
Take the comparison page that ultimately surfaced inside Google's AI Overview answer. It wasn't a happy accident — it was engineered for that exact outcome.
The page opens with a one-paragraph direct answer to the comparative query. Each section heading is phrased as a question. A clean comparison table contrasts Knight against the nationwide operators by service scale, footprint, and approach. The entire page is wrapped in Article + FAQPage schema so the structure is also legible to machines.
Then the off-site work: the same comparison was echoed across two directory listings and an industry article, giving the model the cross-source corroboration it needs before quoting a smaller brand against incumbents.
The GEO Principle
"The page LLMs cite is the page that gives them the cleanest, most corroborated, most quotable answer — not the page that ranks #1."
Prompt-Level Targeting
Three live prompts. Threeengineeredresponses.
GEO doesn't optimise for keywords — it optimises for the questions real people actually type into LLMs. Here's how we mapped intent classes to pages that win them.
Comparative Intent
How does Knight Security NYC compare to other security companies in NYC?
THE PLAY
Dedicated comparison page, table-based contrast vs Allied Universal and Securitas, FAQPage schema, plus directory echoes of the same positioning. → Cited inside live AI Overview.
Informational Intent
What does NYC security guard training involve?
THE PLAY
Lead-with-the-answer course page, Course schema, attributed statistics on duration and certification, and entity-tight links back to the Knight brand. → AI Mode citations.
Evaluative Intent
What should I look for when hiring a security company in NYC?
THE PLAY
Decision-framework article structured as evaluable criteria — exactly the format LLMs lift for "how to choose" prompts. → Cited as the highlighted source.
Results
Six months. Four engines. Measurable citation.responses.
Successfully received 59 reviews, all rated 5 stars, significantly enhancing Granite and Marble Designs’ online reputation and customer trust.
These Reviews showcase the impact of strategic Google Business Profile optimization — driving stronger visibility, deeper customer engagement, and a steady flow of high‑quality local leads that fuel sustainable business growth.
TheGEO Rollout
Six months. Four engines. Measurable citation.responses.
Audit, prompt mapping & competitor citation analysis
Established the GEO baseline: AI Visibility Score of 2, only 2 brand mentions, 10 cited pages. Mapped every Knight page against the real prompts prospects send LLMs and identified which competitors were winning which queries — and why.
Answer-first rewrites & schema deployment
Rewrote core training, eligibility, and course pages around question-led structures with lead-with-the-answer openings. Deployed FAQPage, Course, Organisation, and LocalBusiness schema sitewide. Ran the entity consistency sweep across every page.
Third-party corroboration & directory alignment
Built the off-site evidence trail — targeted training and security directories, review-platform NAP alignment, editorial placements. The objective wasn't backlinks for ranking; it was giving LLMs the cross-source corroboration they require before citing a smaller brand.
Initial AI Overview citations
Mentions climbed into the double digits as Google's AI Overview began surfacing Knight pages for NYC-specific comparison queries. The first proof that the architecture was working — and the first competitive prompts won outright against named incumbents.
AI Mode & Gemini expansion
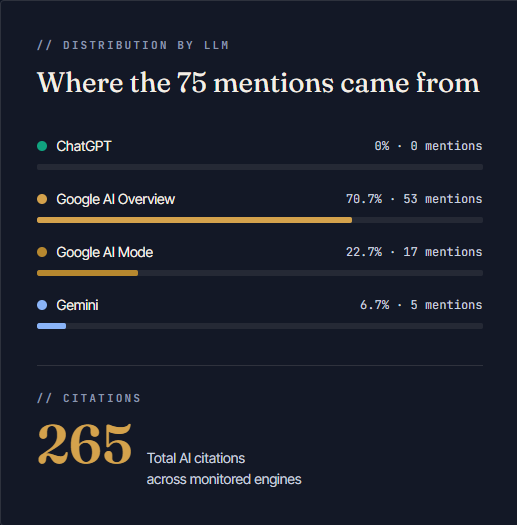
Citation spread beyond AI Overview into AI Mode and Gemini answers. Cited Pages crossed 30 as secondary content earned its own quotes. Bi-weekly tuning sprints reinforced partially-cited pages and added fresh evidence to plateauing topics.
Cited authority across three engines
Final benchmark: 75 mentions, 47 cited pages, 265 total citations, AI Visibility Score of 32 — rated "High" by Semrush's AI Toolkit. A regional brand now competing on the same generative surfaces as national operators many times its size.
GEO In The Wild
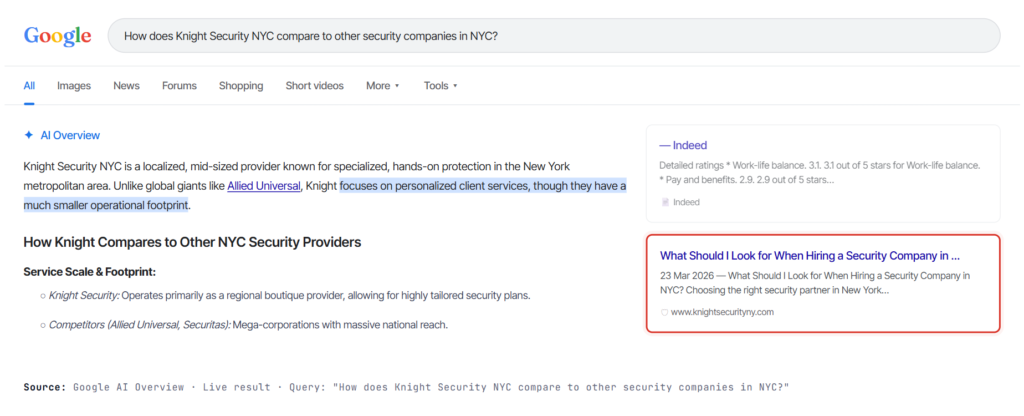
A live AI Overview, citing the brandby name.
A live Google AI Overview response surfacing Knight Security NYC directly inside the generated answer to a comparative query — the exact surface this GEO program was engineered to win.
Your brand belongs inside the answer.
If your competitors are being cited in AI Overview, Gemini, and ChatGPT — and you aren't — you're losing intent before the click ever happens. GEO is how you change that. Let's run your audit.